How to build an AI Assistant for your product
A practical guide for CTOs, product managers and developers building an AI Assistant for their software product.

Note: this isn’t written by ChatGPT - please forgive me for any changes in tone or terminology throughout this post.
4 months ago, we launched Superflows and we have been working closely with our early customers to add AI assistants to their software products. This has exposed us to the biggest challenges that face software companies building these into their products. This post presents these, to help you decide whether building an AI assistant is right for your product.
What's covered
Here's what this post covers:
- Brief definitions so we're on the same page: what's an AI assistant? & why build an AI assistant?
- Design: most important design considerations before you start building
- Build: key engineering decisions & considerations
- Evaluation: how to ensure your AI assistant doesn't make mistakes
- Monitoring: monitoring your AI assistant once in production
- A faster alternative: If all this sounds too much like hard work, we've built a tool to make it easy
What's an AI assistant?
The type of AI Assistant discussed in this post is built into a software product and answers user requests made in natural language. They have 3 key aspects:
- Language input from a user.
- Use a large language model (LLM).
- Connected to a software product, enabling data retrieval and taking actions.
For example, an AI assistant built into a CRM might answer “Show me the top performing salespeople in the US in the last 6 months” by plotting a graph of data from the CRM.
Examples: SeaGPT, Miro Assist, Mixpanel Spark and Shopify Sidekick.
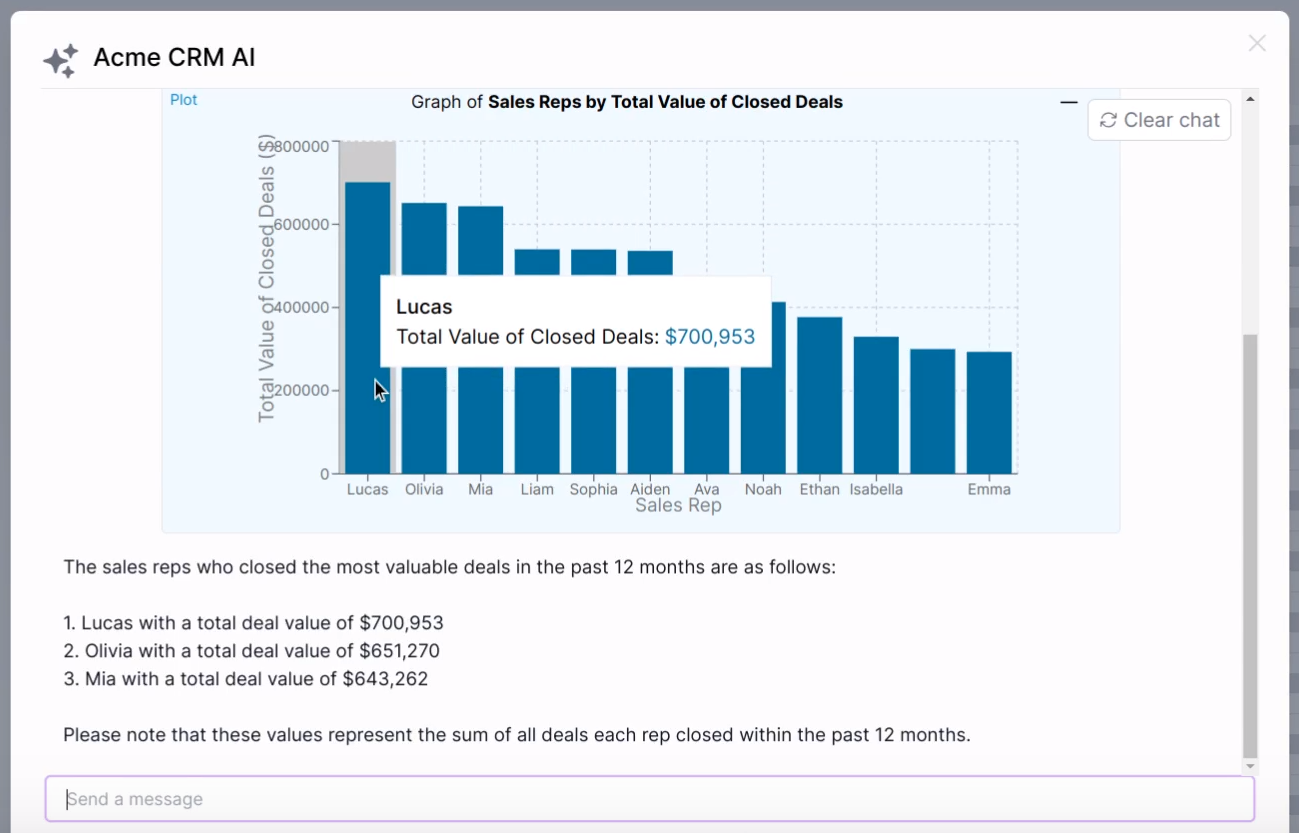 Superflows AI Assistant connected to a CRM, plotting total closed deal value by salesperson over the past 12 months.
Superflows AI Assistant connected to a CRM, plotting total closed deal value by salesperson over the past 12 months.
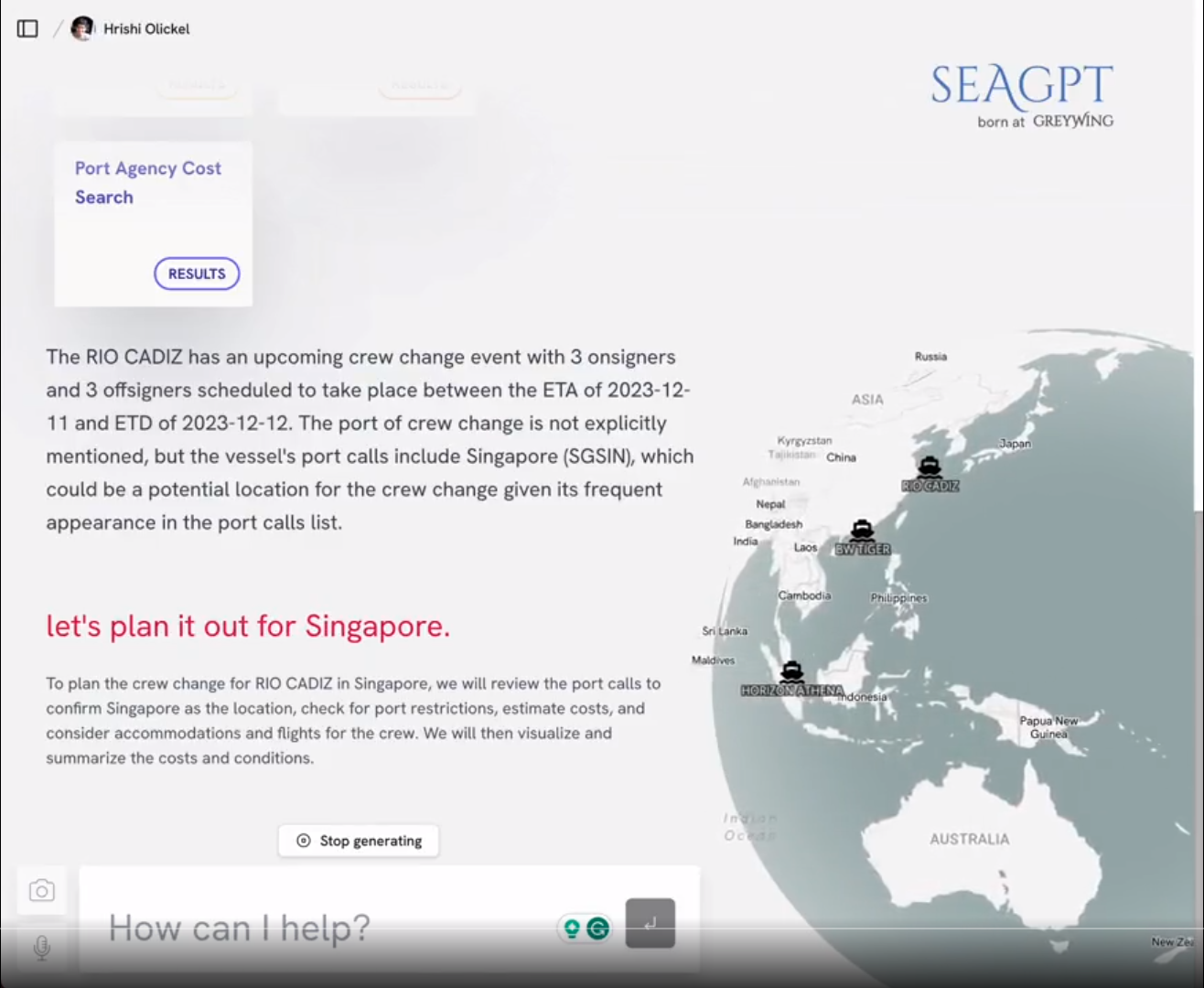 SeaGPT demonstration
SeaGPT demonstration
Why build an AI assistant?
LLMs offer huge potential to make software easier to use. There are 2 parts to this:
1. Replacing slow tasks in your software
Tasks are usually slow for one of 2 reasons.
Either they require specialist skills (E.g. writing Excel formulas to generate plots), which leads to users requiring help from a colleague.
Or they require repetitive sequences of point-and-click actions (E.g. checking all signed employee contracts in the HR system contain a specific clause).
2. Removing the need to learn how to use software
Instead of having to learn how to use business software, you can just ask your AI assistant to do tasks for you. My favourite analogy is flying a plane. Non-LLM software requires teaching new users about every button and switch in the cockpit. An AI assistant is the equivalent of having a trained pilot who does the actual flying, who you can give high-level commands to. E.g. You tell the AI assistant “Land the plane”, and it does.*
Both boil down to:
Save users time
However, LLMs require totally different engineering practices to deterministic code. Language input is unbounded in a way that point-and-click interaction isn’t.
And LLMs aren't deterministic. It's impractical to write tests which covers every request a user could make.
This is why so many of the GenAI demos you see are little more than that. They’ll work for a handful of curated cases, but when stressed in reality, they collapse. They’re slow and unreliable.
Building useful AI assistants is hard.
But with the current state of LLMs, it’s possible to build AI assistants which are useful. Hopefully this guide will help you do that.
* Due to safety implications this would be a terrible use-case for an AI assistant.
Design
Accept some imperfection
Taking unbounded language input from a user means there’s a near-infinite number of queries a user could make. Therefore, formal verification that the AI assistant won’t make a mistake is unfeasible. Given this, if you’re building an AI assistant, you’ll have to live with it making mistakes.
The question is what % of errors you are willing to accept. With companies we’ve worked with, we find deciding on a target reliability to be helpful. 90% is achievable. 99% is in “this-is-very-hard” territory.
Don’t build an AI assistant for use-cases where mistakes are dangerous.
Limit the scope
Instead of building an AI assistant which can do everything (badly), design assistants for the specific use-cases that will save users time
This is a very common mistake. It’s tempting to want an AI assistant that can do everything - an AI that can select between 1000s of actions, plot the outputs and make you a coffee. However, until more powerful models are released, this is unrealistic.
Limit the scope. Focus on AI-generated reports. Or on an eCommerce site, on the listed products, and have the assistant only live on the ‘products’ page. Or on retrieving information from user-uploaded PDFs.
As the number of different tasks your AI assistant can do grows, so does the prompt length and complexity.
LLM outputs deteriorate in quality as the prompt complexity grows. So giving the LLM access to more capabilities tends to reduce its reliability.
Don’t be fooled by recent LLMs having remarkably long context-windows. These are implemented using approaches which degrade their reliability when dealing with long prompts.*
From a UX perspective - would you rather the AI assistant can do a small number of things with 99% reliability? Or would you prefer it being able to do anything in your software with a 80% reliability?
In practice, we have found the best way to set the scope is to make a list of user requests you want your v1 to be able to answer. Then, once version 1 is built, you can expand to these other less valuable use-vases in future versions.
*For the technically-inclined: long context windows tend to be implemented using attention on a subset of tokens in the prompt. This makes attention cheaper to compute (since it doesn't have O(n^2) complexity) on long context windows, but comes at the cost of reliability. Read more here.
Chat UI: yes or no?
The two options typically discussed are a ChatGPT-style chatbot and a text box with a ‘submit’ button.
This is a false dichotomy. Often, the best option is a temporary chat window. Poorly specified requests from users are common. A temporary chat window enables clarification questions to help the user specify their request.
E.g. In a CRM assistant, a user could ask “Show highest deal values”. With no other context, it’s unclear what they mean. The currently open deals? Or only deals that were won? Over what timeframe? And how would they like that to be displayed? As a table? A bar chart?
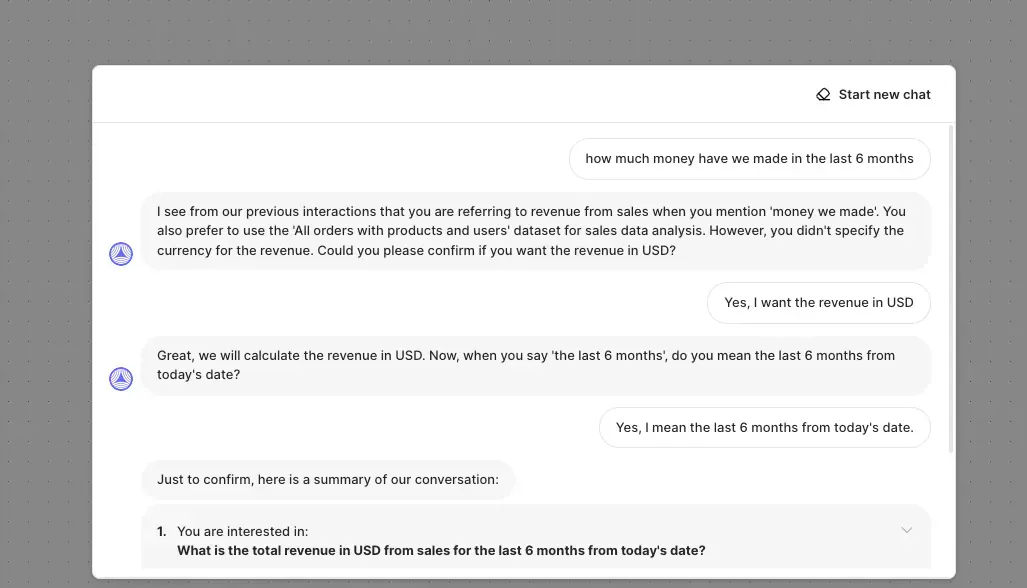 Fluent’s temporary chat interface is a great example of this third option in practice.
Fluent’s temporary chat interface is a great example of this third option in practice.
Other design considerations
- Confirmation UI for potentially damaging actions if a mistake is made, if any exist. E.g. “Are you sure you want to delete all contacts?”
- Personalising responses based on who the user querying is. E.g. in an analytics tool, a data analyst will be keen to get a deeper, more statistical understanding of the data than a business user. This goes beyond the data the AI has access to and into how the data is presented.
- Suggesting requests to the user to steer them. This can be towards what the AI assistant is best at or towards the most valuable actions in your platform. These can come in several forms: suggestions when you open the AI assistant, Google-style auto-completed suggestions as you type and suggested follow-up questions based on the conversation thus far.
Build
This discussion of the considerations when building an AI Assistant is far from exhaustive. It only focuses on couple of key aspects.
LLM engineering
A lot has been written on prompt engineering. For prompt engineers, I strongly recommend Hrishi Olickel’s “Everything I’ll forget about prompting LLMs”.
The key points I’d like to mention are:
- Re-stress the importance of breaking down a problem into chunks that an LLM is competent at. LLMs are better at some problems than others. Typically, it’ll do better at simple problems where the criteria for what it’s doing is very clear.
- With new flagship LLMs being released most weeks, your LLM choice is no longer obvious. Until recently, OpenAI was the only show in town. But now, for specific tasks this is no longer the case. Phind’s finetune of CodeLlama2-34B beats GPT4 at coding. Mistral’s Mixtral model is better than GPT3.5 on numerous tasks.
Assistant Architecture
The assistant architecture is how you decide to split up the task of responding to user requests into chunks which can be solved well by a single LLM call.
There isn’t a simple one-size-fits-all approach that works well for any AI assistant. The architecture chosen must reflect the use-cases you intend it to solve.
If you want it to be able to plot graphs, it’ll probably need to include a code or SQL execution step. If you want it to be able to perform multi-step actions, you’ll need to include a loop to repeatedly include the API responses in subsequent prompts.
The images below show 2 example architectures from Superflows.
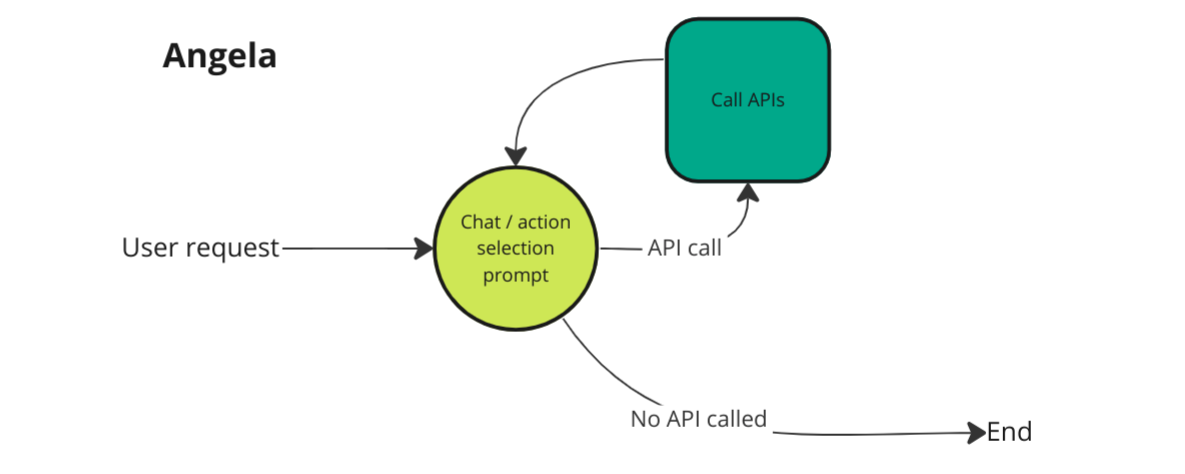
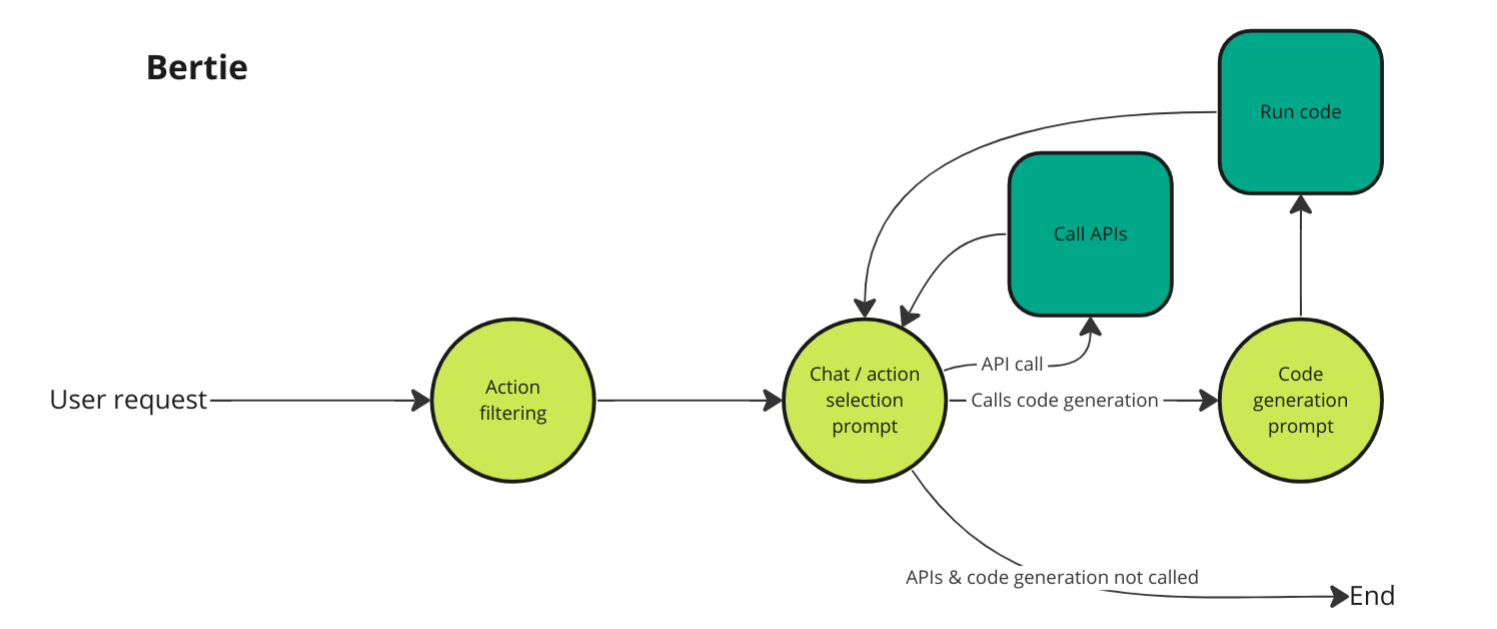 Angela & Bertie - two iterations of AI assistant architecture used in Superflows
Angela & Bertie - two iterations of AI assistant architecture used in Superflows
Other elements/features
This post is long so I’m skipping in-depth discussions of:
- Building in RAG capabilities if necessary. Requires a vector database. This is well-discussed elsewhere.
- Caching strategies - you can save money and reduce response time by reusing the AI’s reasoning from similar requests.
- Using OpenAI’s Assistants API: all the developers I’ve spoken to who have tried it seemed to struggle with getting it to work well. This is partly because the logic of why functions are called isn’t clear. This makes prompt changes hard to reason about. It's also slower than using their API directly and doesn't support streaming (where words appear one-by-one)
- Using OpenAI’s built-in function-calling: by the LLMs only being able to output function calls or text, chain-of-thought in a single prompt is impossible. This makes using it slower (more HTTP round trips) and more expensive (more API calls). But it’s a good way to get started.
Evaluation
Before deploying, you want to ensure that the AI assistant you’re building hits your target reliability.
We’ve seen the best results from splitting this into 4 questions:
- How well does your AI assistant respond to the use-cases you’re hopeful it’ll solve?
- How does it respond to unclear user requests?
- How does it respond to impossible requests which sound plausible?*
- How does it respond to irrelevant questions?
You’ll want an evaluation set for each type of user request, then run end-to-end tests. The allowable error tolerance in each category may be different. Some mistakes are worse than others. Incorrectly bulk deleting data from a user’s account is much worse than the AI erroneously saying it can’t help you with a request.
Creating these datasets can be time-consuming. However, LLMs can be used along the way to generate questions (particularly irrelevant and unclear questions) and write first versions of answers, which can be checked by humans.
Automating evals speeds up the evaluation process considerably. Code-based evals are fast and can check whether the correct functions are called and graphs are plotted. Using LLMs to judge the output can also be effective, primarily to judge if the text output by the LLM gives ‘correct’ answers for each category. E.g. “this request is impossible”.
Once you’re happy with the assistant’s performance on automated evals, it’s worth human-checking a sample of each category to ensure the tone is suitable.
* E.g. suppose your CRM’s AI assistant can search deals, but can’t delete them. Then the request “Delete all my deals” sounds plausible, but isn’t possible.
Monitoring
Suppose you finally put your AI assistant into production. Great!
Now you need a suite of monitoring tools to see what users are actually using it for. These questions are commonly asked:
- What requests do users actually make?
- Where does the assistant make mistakes?
- Who keeps coming back to using it?
- What are the most common requests that it fails to achieve most frequently?
- Who uses it the most?*
You’ll want to set up an analytics tool to answer these in an ongoing fashion. For this, Langfuse (OSS) and Context.ai look promising - we’re yet to use either in anger.
* Since LLM providers charge per usage, you may need to impose user or team-based usage limits. This provides an opportunity to upsell the AI assistant by offering further requests (like Notion AI) and drive revenue.
A faster alternative
Superflows makes it easy to set up an AI assistant which makes API calls and plot the outputs to answer user requests. It means you don’t have to delve into prompt engineering or assistant architecture - this is all handled for you. It’s open source and LLM-agnostic - meaning you aren’t getting locked into using 1 LLM provider.
It comes with caching, suggestions, personalisation, confirmation and RAG all built-in. We support the majority of common use-cases: plotting graphs & reports, batch and multi-step actions and querying documentation. We also offer easy integration with our React frontend components, basic evaluation with a playground to test the assistant and monitoring with usage tracking.
We will soon be adding further evaluation and monitoring features.
Click the image below to watch a 30s video of a Superflows AI assistant in action.
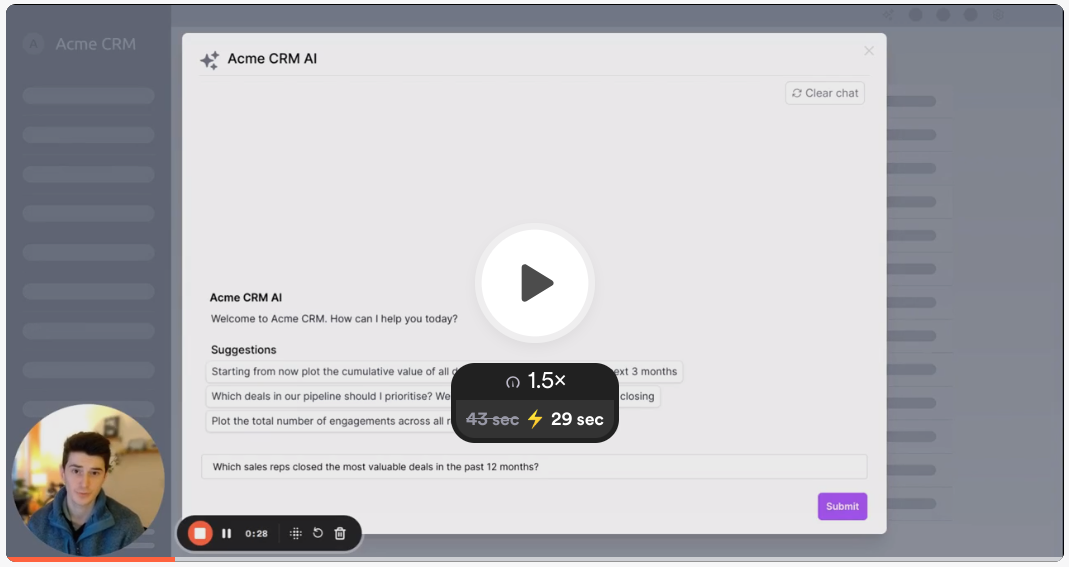 Superflows AI assistant connected to a CRM, plotting data retrieved from its API
Superflows AI assistant connected to a CRM, plotting data retrieved from its API
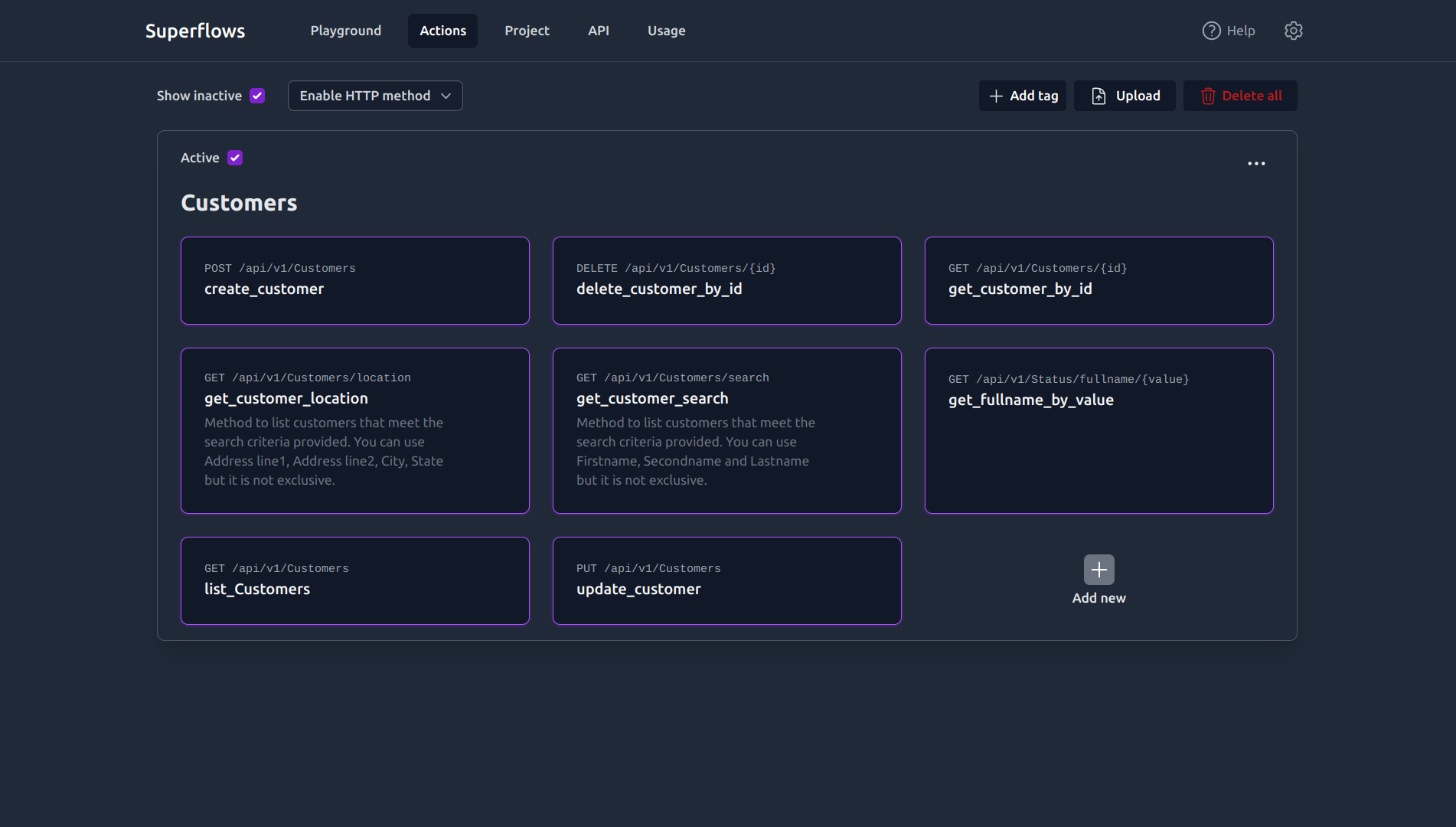 Superflows developer dashboard
Superflows developer dashboard
You can try out the CRM demo here.
Get started building your AI assistant on the dashboard here.
I hope you find this guide useful!
Please send any feedback to henry@superflows.ai.